데이터를 훈련, 검증, 테스트 세트로 나누는 것은 간단해 보일 수 있지만 데이터가 적을 때는 몇가지 기법을 사용하면 도움이 된다. 대표적인 세 가지 평가 방법인 hold-out validation, K-fold cross-validation, iterated K-fold cross-validation에 대해 알아보자.
1. hold-out validation
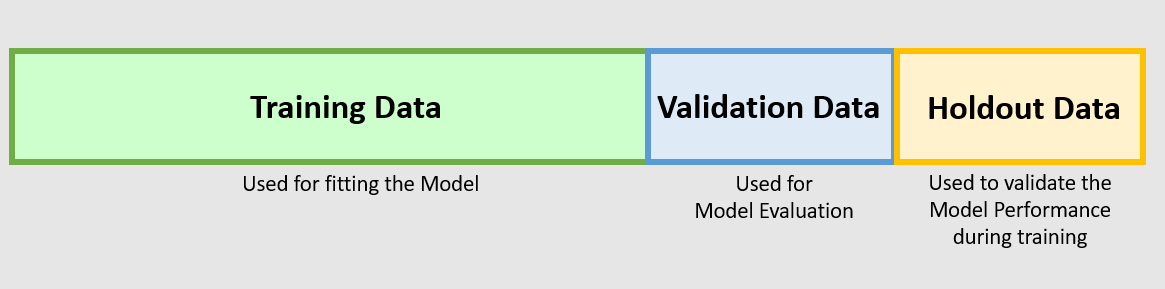
데이터의 일정량을 테스트 세트로 떼어 놓는다. 남은 데이터에서 휸련하고 테스트 세트로 평가한다. 정보 누설을 막기 위해 테스트 세트를 사용하여 모델을 튜닝해서는 안된다. 이런 이유로 검증 세트도 따로 떼어 놓아야 한다.
다음 코드는 간단한 구현 예이다.
num_validation_samples = 10000
np.random.shuffle(data) # 데이터를 섞는 것이 일반적으로 좋다.
validation_data = data[:num_validation_samples] # 검증 세트를 만듬.
data = data[num_validation_samples:]
training_data = data[:] # 훈련 세트를 만듬
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data) # 훈련 세트에서 모델을 훈련하고 검증 세트로 평가한다.
# 다시 모델을 튜닝, 다시 훈련, 평가, 다시 튜닝....
model = get_model()
model.train(np.concatenate([training_data, validation_data])) # 하이퍼파라미터 튜닝이 끝나면 테스트 데이터를 제외한 모든 데이터를 사용하여 모델을 다시 훈련.
test_score = model.evaluate(test_data)이 평가 방법은 단순해서 한 가지 단점이 있다. 데이터가 적을 때는 검증 세트와 테스트 세트의 샘플이 너무 적어 주어진 전체 데이터를 통계적으로 대표하지 못할 수 있다.
2. K-fold cross validation
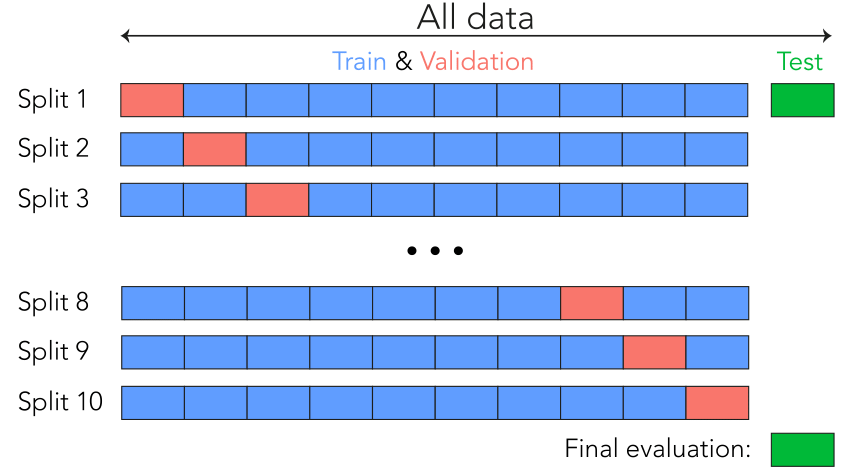
이 방식에서는 데이터를 동일한 크기를 가진 K개 분할로 나눈다. 각 분할 i에 대해 남은 K-1개의 분할로 모델을 훈련하고 분할 i에서 모델을 평가한다. 최종 점수는 이렇게 얻은 K개의 점수를 평균한다. 이 방법은 모델의 성능이 데이터 분할에 따라 편차가 클 때 도움이 된다.
다음은 간단한 구현 예이다.
k = 4
num_validation_samples = len(data) // k
np.random.suffle(data)
validation_scores = []
for fold in range(k):
validation_data = data[num_validation_samples * fold:
num_validation_samples + (fold + 1)] # 검증 데이터 부분을 선택한다.
training_data = data[:num_validation_samples * fold] +
data[num_validation_samples * (fold + 1):] # 남은 데이터를 훈련 데이터로 사용한다.
model = get_model() # 훈련되지 않은 새로운 모델을 만든다.
model.train(training_data)
validation_score = model.evaluate(validation_data)
validation_scores.append(validation_score)
validation_score = np.average(validation_scores) # 검증 점수 : K개 폴드의 검증 점수 평균
model = get_model()
model.train(data)
test_score = model.evaluate(test_data)3. iterated K-fold cross-validation
이 방법은 비교적 가용 데이터가 적고 가능한 정확하게 모델을 평가하고자 할 때 사용한다. 캐글 경연에서는 이 방법이 유용하게 사용된다고 한다. 이 방법은 K-fold CV을 여러 번 적용하되 K개의 분할로 나누기 전에 매번 데이터를 무작위로 섞는다. 최종 점수는 모든 K-fold CV을 실행해서 얻은 점수의 평균이 된다. 결국 P x K개의 모델을 훈련하고 평가하므로 비용이 매우 많이 든다.